Capak Research Areas:
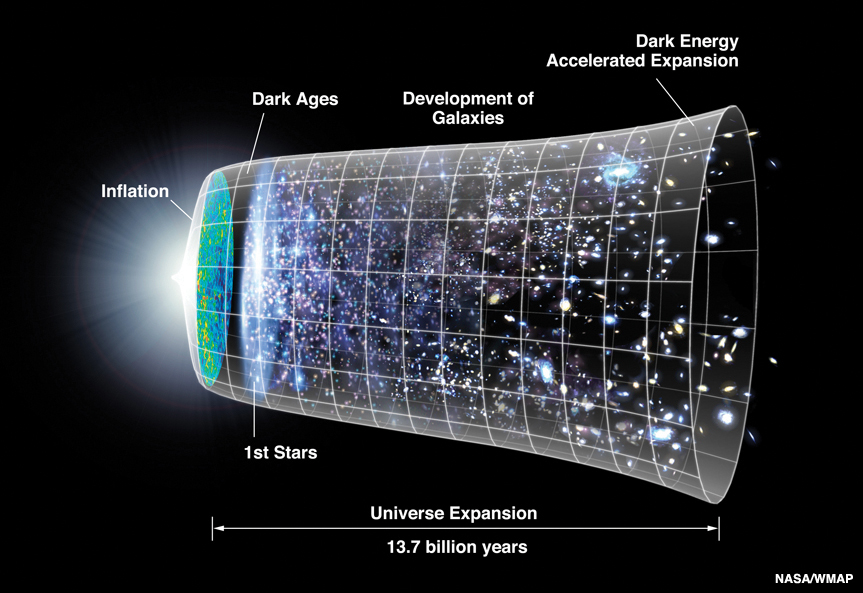
I focused the research of my group at the California Institute of Technology (Caltech) on how the universe started and why it behaves the way it does. To do this we used surveys of galaxies to measure the properties of space and time such as the nature of Dark Matter, Dark Energy, and the cosmic inflation that is thought to have happened in the first-second after the big bang. Along the way we also learn a lot about how stars and galaxies form and the role of exotic phenomenon like black holes and starburst galaxies in shaping this evolution. My group successfully carried out some of the largest ever programs on the Hubble Space Telescope, the Spitzer Space Telescope, the Chandra X-Ray observatory, the Keck Telescope, the Subaru Telescope, ALMA, and the Jansky Very Large Array. Before I transitioned to Oculus in 2020, my research group was focused on dedicated cosmology projects including Euclid, SPHEREx, WFIRST, and CASTOR the work of which continues.
We worked with large and complex data sets consisting of pictures in 10 to over 1000 colors of light and the signals we were searching for are weak and influenced by rare events. So, to make measurements of the Universe we developed expertise in data science, hyper-spectral image analysis, statistics and machine learning. Specifically, we developed machine learning methods to model data and combined it with domain knowledge including physical models. We made significant progress towards developing a statistical model of the galaxy population. This model is unique because it strives to be accurate enough to enable cosmology and precise enough to identify rare sources in new data sets.
Machine Learning for Cosmology and Galaxy Evolution
Studies of cosmology (the properties of space-time) requires precise control of systematics in noisy but large data sets. Studies of galaxy evolution require extracting trends from noisy and incomplete data. Both domains are well suited to machine learning but require using domain knowledge in the form of data properties and physical models to extract information.
At Caltech we developed machine learning and statistical techniques that allowed for effective use of astronomical domain knowledge. The work included identifying the optimal objects to target for follow-up observations, modeling and de-convolving errors from complex high-dimensional data sets and accelerating computationally expensive model fitting.
Observational Cosmology and Galaxy Evolution
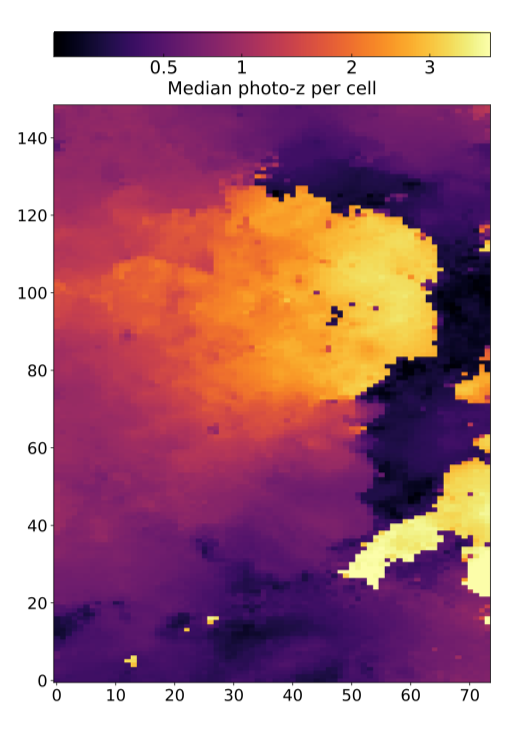
The study of observational cosmology is using light one can see from galaxies and stars to understand the un-seen properties of space-time like Dark Matter and Dark Energy. However, a single measurement of light contains very little information on the nature of space-time. For instance, the shape of a galaxy is changed by less than 1% due to the combination of Dark Matter and Dark Energy through a process known as weak gravitational lensing. So, astronomers studying cosmology must average over billions of galaxies. In practice, this means observing as much of the sky as possible.
While at Caltech I focused on modeling the galaxy population well enough to make precision inferences about cosmology and then used those cosmology measurements to improve our understanding of galaxies. This research required developing a comprehensive statistical model of the galaxy population that can be continuously improved as the datasets get better. For cosmology measurements this model enabled us to better estimate the distance to galaxies, and hence how long ago the light left the galaxy. For galaxy evolution measurements it enabled us to measure how galaxies changed over time and identify important but rare types of galaxies that could teach us about specific physical processes.
The remaining members of the group at Caltech are still actively involved in the Euclid, SPHEREx, and the WFIRST cosmology teams. They are leading the C3R2 survey on Keck and VLT aimed at enabling weak lensing cosmology with photometric redshifts.
The Early Universe
The first billion years after the big bang is one of the best periods of time to study the connection between cosmology (the nature of space-time) and the formation of galaxies. At this point in the Universe, there is not much time for the physics of galaxy formation to become complicated. However, studying this period of time requires special data-science tools to differentiate rare objects in the distant Universe from similar looking objects that are closer by. In addition, specialized statistical tools are required to link the measurements of these distant galaxies to physical models and simulations of how galaxies are expected to evolve under different theories.
At Caltech my group helped found the Cosmic Dawn Center in Copenhagen, Denmark, and led the largest programs ever granted on the Spitzer Space Telescope which led to the Cosmic Dawn Survey. We were also leaders in the ALPINE, BUFFALO, projects aimed and finding and characterizing the high-redshift Universe. In the past we were also leaders in the COSMOS, GOODS, VUDS, Frontier Fields, CCAT, and SEIP/SAFIRES projects.